Note: You can find all the code at every step of the process in my GitHub repository https://github.com/martinberoiz/daemon.
A daemon is a basically a background process; a program that runs continuously, most of the time waiting for external input to do specific work.
In this article I explain how to write and deploy a Linux systemd service using Python.
Linux adopted systemd as its “System and Service Manager”, replacing the previous init system.
Systemd is tasked with starting and managing several “services”, ie., background processes that provide system functionality on demand.
It is customary to add the letter d (for daemon) to programs that will run as services.
Run a Python script as a background process
So, starting from the basic, Python scripts are files that are meant to run from the command line.
For example
import time
DELAY = 10
while True:
time.sleep(DELAY)
print("Hello from a script!"
" It's been {} seconds since last time.".format(DELAY))
If we run it,
$ python myscript.py
It will run forever and print a statement every 10 s.
To stop it, simply enter ctrl+c (^C) on the console and it will kill the running process.
To make the process run in the background, we can append & to the command
$ python myscript.py &
The use of the end ampersand will push myscript to the background and return the prompt for the next command. This way we have created a background process.
There are two problems with this approach.
The first one is that the process is terminated as soon as the user logs off.
The second is that there is no redirection of stdout and stderr (we could improve the example with pipes redirecting these two, but it’s beyond the scope of this article).
To remedy these, we can use the command nohup, which is a POSIX command that ignores terminal’s termination signal once we log out, so that the process can keep running.
$ nohup python myscript.py &
This last command would be enough to create a daemon, and we could finish our tutorial at this point.
Note: To terminate background processes initiated by nohup or appending ampersand, you can find the process PID with `ps -e` and terminate with `kill`
$ ps -e | grep python ... 17490 ttys000 0:00.03 python myscript.py ... $ kill 17490
Systemd Services
We can also make use of systemd to launch the process at start-up and restart it whenever it crashes to make sure we can always have it running. Systemd also provides a unique interface to start, stop and restart services. This last one (restart) is useful if we changed any configuration file and we want to restart the service with the new one.
The process to create a systemd service is fairly simple. All we need to do, is create a .service file in /etc/systemd/system/ directory with the name of the service.
For our example we’ll use the file name mydaemond.service. Like we said before, it is customary to append a letter d after the service name.
Below is a minimal example of a service file.
We will copy the following to the file /etc/systemd/system/mydaemond.service
(Like we said before, it is customary to append a letter d after the service name.)
[Unit] Description=My Awesome Service After=network.target [Service] Type=simple ExecStart=/home/myuser/myscript.py Restart=on-failure
Once the file is created we can start our service invoking `systemctl`:
$ systemctl start mydaemond
And stop it:
$ systemctl stop mydaemond
Simplifying the installation
Installing the python module with pip
It may be convenient to provide our users with an easy way to install both our python script and to register our service.
The standard way to install packages in Python is using pip, and for that we need a setup.py file.
A minimal setup.py to install a Python module looks like this:
from setuptools import setup
setup(name='mymodule',
version='0.1',
description='My Awesome Python Module',
py_modules=['myscript', ],
)
The difference between a Python module and a Python script is that the former is intended to be imported inside other modules or scripts, while the latter is intended to be run completely from the command line.
Modules don’t usually have executable instructions in the global scope, only function definitions (and occasional variable declarations).
Scripts, on the other hand, have mostly executable instructions in the global scope.
We have written a script myscript.py so far (not a module), so this setup.py file would not help us.
We can reach a compromise between a module and a script, however, by encapsulating functionality in function definitions and only call them on the condition that it’s run from the command line.
Let’s modify our myscript.py like this:
import time
DELAY = 10
def main():
while True:
time.sleep(DELAY)
print("Hello from a script!"
" It's been {} seconds since last time.".format(DELAY))
If we run the script as it is, nothing will be done because the main loop is inside a function that is never called. On the upside, importing it will not do any harm, since the loop is not going to be executed.
Most importantly, our script can already be installed with pip:
$ pip install . $ python >>> import myscript >>> myscript.main() Hello from a script! It's been 10 seconds since last time. Hello from a script! It's been 10 seconds since last time. ...
It will still do nothing if executed from the command line:
$ python myscript.py $
Python modules that can be executed from command line
To fix our broken script, what we need is to add a condition at the end of the file that calls main() only if it’s being executed as a script.
How can we detect if our code has been called from the command line or imported from a module?
When we import our code, python fills the module .__name__ variable to the called module’s name
For example:
import numpy as np print(np.__name__)
Will print the string numpy, which is the name of the imported module.
But when the module is not imported but rather called from the command line, Python will populate the __name__ variable with the string “__main__”.
So we can bifurcate the code in our script and execute main() only when it’s intended to be run as a script:
import time
DELAY = 10
def main():
while True:
time.sleep(DELAY)
print("Hello from a script!"
" It's been {} seconds since last time.".format(DELAY))
if __name__ == "__main__":
main()
This time calling myscript.py from the command line will run forever as it is intended, but importing it as a module will not hang our computer in an infinite loop.
With this modification, our script can be installed as a module with pip as before but can be also run from the command line.
$ python myscript.py Hello from a script! It's been 10 seconds since last time. Hello from a script! It's been 10 seconds since last time. ...
Using pip to create an installable script
Using setuptools gives us an extra feature, which is, that now pip can create a small script from our module and place it in our $PATH. If it is installed in a virtual environment, it will be installed in the `bin/` directory, it it is installed globally, it will be installed in /usr/local/bin.
To create this script, we just have to modify our setup.py like this:
from setuptools import setup
setup(name='mymodule',
version='0.1',
description='My Awesome Python Module',
py_modules=['myscript', ],
entry_points={
'console_scripts': [
'mydaemon = myscript:main',
],
},
)
If we install this with pip, it will create two things.
First, it will install myscript.py as a module (so it can be imported as `import myscript`), this is of not much use for this example.
Secondly, it will create a mydaemon script, which basically calls main from myscript.
$ mydaemon Hello from a script! It's been 10 seconds since last time. Hello from a script! It's been 10 seconds since last time. ...
This mydaemon is the one we will use as the systemd service.
You can check that the previous functionality still works as expected.
Automating the installation of the systemd unit
We could ask our user to edit and copy himself the file mydaemond.service, but instead we will create a makefile, which is more familiar to most Linux users, and make the installation process easier.
all: mydaemon mydaemond.service
.PHONY: all mydaemon install uninstall clean
service_dir=/etc/systemd/system
awk_script='BEGIN {FS="="; OFS="="}{if ($$1=="ExecStart") {$$2=exec_path} if (substr($$1,1,1) != "\#") {print $$0}}'
mydaemon: myscript.py setup.py
pip install .
mydaemond.service: myscript.py
# awk is needed to replace the absolute path of mydaemon executable in the .service file
awk -v exec_path=$(shell which mydaemon) $(awk_script) mydaemond.service.template > mydaemond.service
install: $(service_dir) $(conf_dir) schedulerd.service scheduler.conf.yml
cp mydaemond.service $(service_dir)
uninstall:
-systemctl stop mydaemond
-rm -r $(service_dir)/mydaemond.service
clean:
-rm mydaemond.service
The makefile makes use of a .service template file, that we provide below.
# mydaemond.service.template [Unit] Description=My Awesome Service After=network.target [Service] Type=simple ExecStart=/home/myuser/myscript.py Restart=on-failure
Now to install the service, we just need to make and make install.
$ make $ sudo make install
The installation requires root permissions because it will copy files over /etc/ which is usually owned by root.
The makefile will basically replace the full path of the mydaemon executable into the ExecStart line using awk and then copy the file over to /etc/.
Makefile commands clean and uninstall are also provided for convenience.
![\left[ \begin{array}{c} i' \\ j' \\ k' \end{array} \right] = \begin{bmatrix} i'.i & i'.j & i'.k\\ j'.i & j'.j & j'.k \\ k'.i & k'.j & k'.k \end{bmatrix} \left[ \begin{array}{c} i \\ j \\ k \end{array} \right] = \left[ \begin{array}{c} i' \rightarrow \\ j' \rightarrow \\ k' \rightarrow \end{array} \right] \left[ \begin{array}{c} i \\ j \\ k \end{array} \right] \equiv R \left[ \begin{array}{c} i \\ j \\ k \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D++++i%27+%5C%5C++++j%27+%5C%5C++++k%27++++%5Cend%7Barray%7D+%5Cright%5D++++%3D+%5Cbegin%7Bbmatrix%7D+i%27.i+%26+i%27.j+%26+i%27.k%5C%5C++++j%27.i+%26+j%27.j+%26+j%27.k+%5C%5C++++k%27.i+%26+k%27.j+%26+k%27.k++++%5Cend%7Bbmatrix%7D++++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+i+%5C%5C++++j+%5C%5C++++k+%5Cend%7Barray%7D+%5Cright%5D+%3D++++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+i%27+%5Crightarrow+%5C%5C++++j%27+%5Crightarrow+%5C%5C++++k%27+%5Crightarrow+%5Cend%7Barray%7D+%5Cright%5D++++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+i+%5C%5C++++j+%5C%5C++++k+%5Cend%7Barray%7D+%5Cright%5D+%5Cequiv+R+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+i+%5C%5C++++j+%5C%5C++++k+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
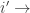 means write the components of i’ in the {i,j,k} base in that row. For any other vector (x’,y’,z’) the transformation is the same. It can be seen by writing
means write the components of i’ in the {i,j,k} base in that row. For any other vector (x’,y’,z’) the transformation is the same. It can be seen by writing
 since it is an orthonormal matrix).
since it is an orthonormal matrix).![\left[ \begin{array}{c} i' \rightarrow 0 \\ j' \rightarrow 0 \\ k' \rightarrow 0 \\ 0 \ldots 1 \end{array} \right] = \begin{bmatrix} R_0 & R_4 & R_8 & R_{12} \\ R_1 & R_5 & R_9 & R_{13} \\ R_2 & R_6 & R_{10} & R_{14} \\ R_3 & R_7 & R_{11} & R_{15} \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D++++i%27+%5Crightarrow+0+%5C%5C++++j%27+%5Crightarrow+0+%5C%5C++++k%27+%5Crightarrow+0+%5C%5C++++0+%5Cldots+1++++%5Cend%7Barray%7D++++%5Cright%5D+%3D++++%5Cbegin%7Bbmatrix%7D+R_0+%26+R_4+%26+R_8+%26+R_%7B12%7D+%5C%5C++++R_1+%26+R_5+%26+R_9+%26+R_%7B13%7D++++%5C%5C+R_2+%26+R_6+%26+R_%7B10%7D+%26+R_%7B14%7D++++%5C%5C+R_3+%26+R_7+%26+R_%7B11%7D+%26+R_%7B15%7D++++%5Cend%7Bbmatrix%7D+&bg=ffffff&fg=333333&s=0&c=20201002)

 will be replaced by a linear combination of the rotation terms and the translation terms.
will be replaced by a linear combination of the rotation terms and the translation terms.